
ELK-MS - ElasticSearch/LogStash/Kibana - Mesos/Spark : a lightweight and efficient alternative to the Hadoop Stack - part III : so why is it cool ?
by Jerome Kehrli
Posted on Wednesday Aug 30, 2017 at 10:43PM in Big Data
Edited 2017-10-30: I was using ES 5.0.0 with Spark 2.2.0 at the time of writing the initial version of this article.
With ElasticSearch 6.x, and ES-Hadoop 6.x, the game changes a little. The Spark 2.2.0 Dynamic allocation system is now perfectly compatible with the way ES-Hadoop 6.x enforces data locality optimization and everything works just as expected.
So, finally the conclusion of this serie of three articles, the big conclusion, where I intend to present why this ELK-MS, ElasticSearch/LogStash/Kibana - Mesos/Spark, stack is really really cool.
Without any more waiting, let's give the big conclusion right away, using ElasticSearch, Mesos and Spark can really distribute and scale the processing the way we want and out of the box /(using Dynamic Allocation) scale the processing linearly with the amount of data to process.
And this, exactly this and nothing else, is very precisely what we want from a Big Data Processing cluster.
At the end of the day, we want a system that books a lot of the resources of the cluster for a job that should process a lot of data and only a small subset of these resources for a job that works on a small subset of data, with a strong enforcement of data locality optimization.
And this is precisely what one can achieve pretty easily with the ELK-MS stack, in an almost natural and straightforward way.
I will present why and how in this article.
The first article - ELK-MS - part I : setup the cluster in this serie presents the ELK-MS stack and how to set up a test cluster using the niceideas ELK-MS package.
The second article - ELK-MS - part II : assessing behaviour presents a few concerns, assesses the expected behaviour using the niceideas ELK-MS TEST package and discusses challenges and constraints in this ELK-MS environment.
This third and last article - ELK-MS - part III : so why is it cool? presents, as indicated, why this ELK-MS stack is really really cool and works great.
This article assumes a basic understanding of Big Data / NoSQL technologies in general by the reader.
Summary
1. Introduction
The reader might want to refer to the Introduction of the first article in the serie as well as the introduction of the second article.
Summarizing them, this series of article is about presenting and assessing the ELK-MS stack, the tests done using the test cluster and present the conclusion, in terms of constraints as well as key lessons.
The second article was presenting the technical constraints coming from integrating Spark with ElasticSearch through the ES-Hadoop connector when running Spark on Mesos.
In this second article I focused a lot on what was not working and what were the constraints. A reader might have had the impression that these constraints could prevent a wide range of use cases on the ELK-MS stack. I want to address this fear in this third article since this is all but true, Spark on Mesos using data from ElasticSearch is really a pretty versatile environment and can address most if not all data analysis requirements.
In this last article, I will present how one can use a sound approach regarding data distribution in ElasticSearch to drive the distribution of the workload on the Spark cluster.
And it turns out that it's pretty straightforward to come up with a simple, efficient and natural approach to control the workload distribution using ElasticSearch, Spark and Mesos.
ES index layout strategies
The parameters that architects and developers need to tune to control the data distribution on ElasticSearch, which, in turn, controls the workload distribution on spark, are as follows:
- The index splitting strategy
- The index sharding strategy
- The replication strategy (factor)
- The sharding key
Spark aspects
Then on the spark side the only important aspect is to use a proper version of ES-Hadoop supporting the Dynamic Allocation System without compromising data locality optimization (i.e ES-Hadoop >= 6.x for Spark 2.2)
But before digging into this, and if that is not already done before, I can only strongly recommend reading the the first article in this serie, related presenting the ELK-MS stack and the second article which presents the conclusions required to understand what will follow.
2. Data locality and workload distribution
What has been presented in the conclusion section of the ELK-MS part II article is summarized hereunder:
- Fine Grained scheduling mode of spark jobs by Mesos screws performances up to an unacceptable level. ELK-MS need to stick to Coarse-Grained scheduling mode.
-
ES-Hadoop is able to enforce data-locality optimization under nominal situations. Under a heavily loaded cluster, data-locality optimization can be compromised for two reasons:
- If the local Mesos / Spark node to a specific ES node is not available after the configured waiting time, the processing will be moved to another free Mesos / Spark node.
- ElasticSearch can well decide to serve the request from another node should the local ES node be busy at the time it is being requested by the local spark node.
-
With ES-Hadoop 5.x, Dynamic allocation was messing up data locality optimization between ES and Spark. As such only Static allocation was usable and it was required to limit artificially the amount of nodes for a given job in good correspondance to the amount of shards in ES (usage of property
spark.cores.maxto limit the amount of spark executors and thesearch_shardsAPI in ES to find out about the amount of shards to be processed)
But now with ES-Hadoop 6.x, Dynamic allocation doesn't interfere with data locality optimization and everything works well out of the box. - Re-distributing the data on the cluster after the initial partitioning decision is only done by spark under specific circumstances.
ES-Hadoop drives spark partitioning strategy
So what happens with ES-Hadoop 6.x and dynamic allocation is that ElasticSearch sharding strategy drives the partitionning strategy of corresponding data frames in Spark. With Data Locality Optimization kicking in, even with Dynamic Allocation enabled, The Spark / Mesos cluster will do its best to create the Spark partitions on the nodes where the ES shards are located.
And this really works just out of the box.
Eventually, there will be just as many executors booked by Mesos / Spark on the cluster as is requiredto handle every ES shars in a dedicated, co-located partition within Spark.
3. Examples
In order to illustrate why I believe that in fact the way ELK-MS behaves when it comes to distributing the workload following the distribution of the data is efficient and natural, we'll use the examples below.
Imagine the following situation: the ELK-MS test cluster contains 6 nodes with similar configurations. The dataset to be stored is called dataset and contains 2 months of data.
In ElasticSearch the indexing settings are as follows:
-
The Index splitting strategy is by month. This is not strictly an ElasticSearch setting, this is configured in Logstash or any other data ingestion tool.
As a matter of fact, whenever one wants to store temporal data in ElasticSearch (timeseries), one naturally considers splitting the index by year, month or even day depending on the size of the dataset. - The sharding strategy consists in creating 3 shards.
- The replication strategy consists in creating 2 replicas (meaning 1 primary shard and 2 replicas).
- We do not care about configuring the sharding key any differently than the default for now (a few words on the sharding key configuration are given in the conclusion).
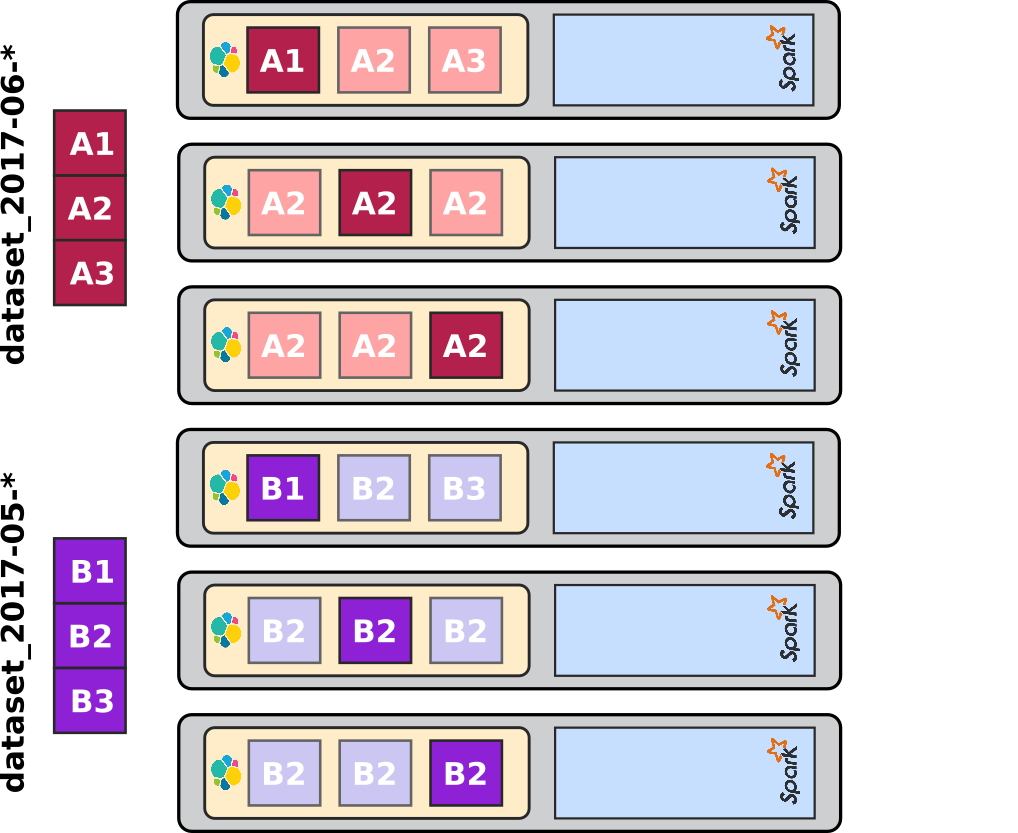
Initial situation
We can imagine that the above situation ends up in the following data layout on the cluster. (One should note though that this is not very realistic since ES would likely not split both month this way when it comes to storing replicas):
Working on a small subset of data for one month
Now let's imagine that we write a processing script in spark that fetches a small subset of the data of one month, June 2017, so [A] here.
In addition, imagine that the filter ends up identifying precisely the data from a single shard of the index. Spark / Mesos would create in this case a single spark partition on the node co-located to the ES shard.
The processing happens this way in this case:
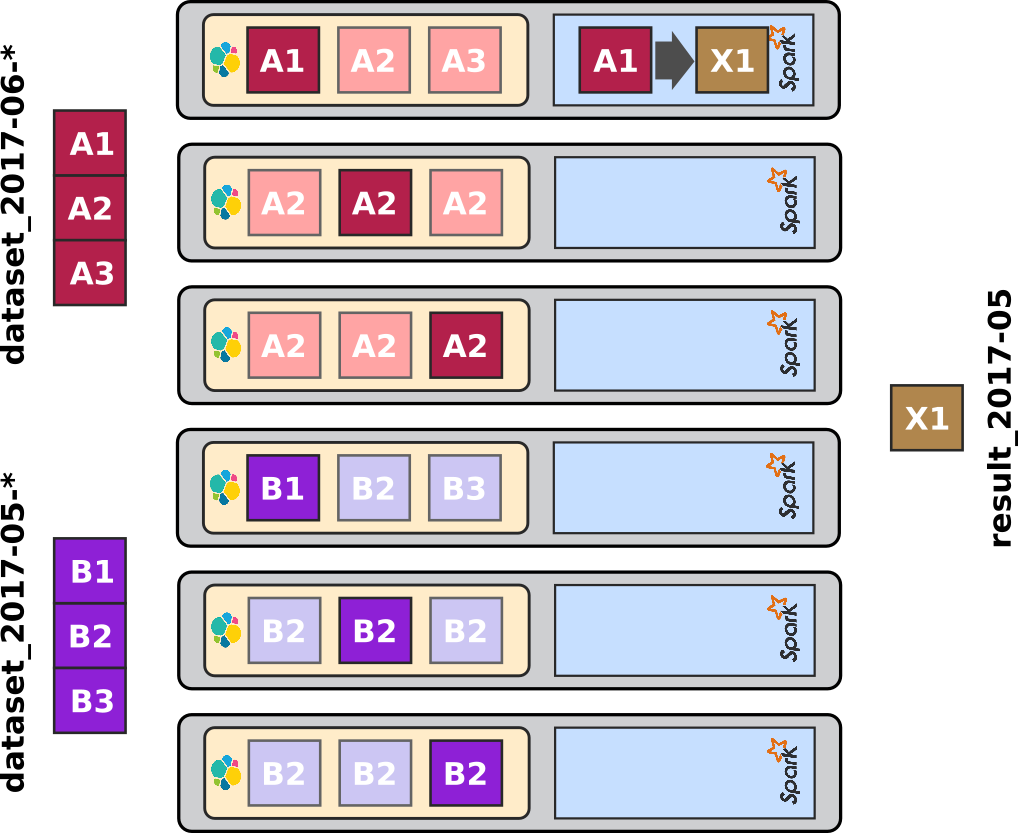
Since only one shard needs to be read from ElasticSearch, ES-Hadoop will drive the creation of a single partition in the resulting DataFrame (or RDD), which in turn will cause Spark to request a single task in one executor, the one local to the ES shard.
So what actually happens is that working on a single shard located on single ES node will actually drive spark in a way to make it work on one single node as well.
Using replicas has the benefits to give the Mesos / Spark cluster some choice in regards to which this node should be. This is especially important if the cluster is somewhat loaded.
Working on a single month of data
In this second example, the processing script works on a single month of data, the full month of June 2017, so all shards of [A] here.
This will drive Spark to create 3 corresponding partitions on the Mesos / Spark cluster.
The processing works as follows in this case:
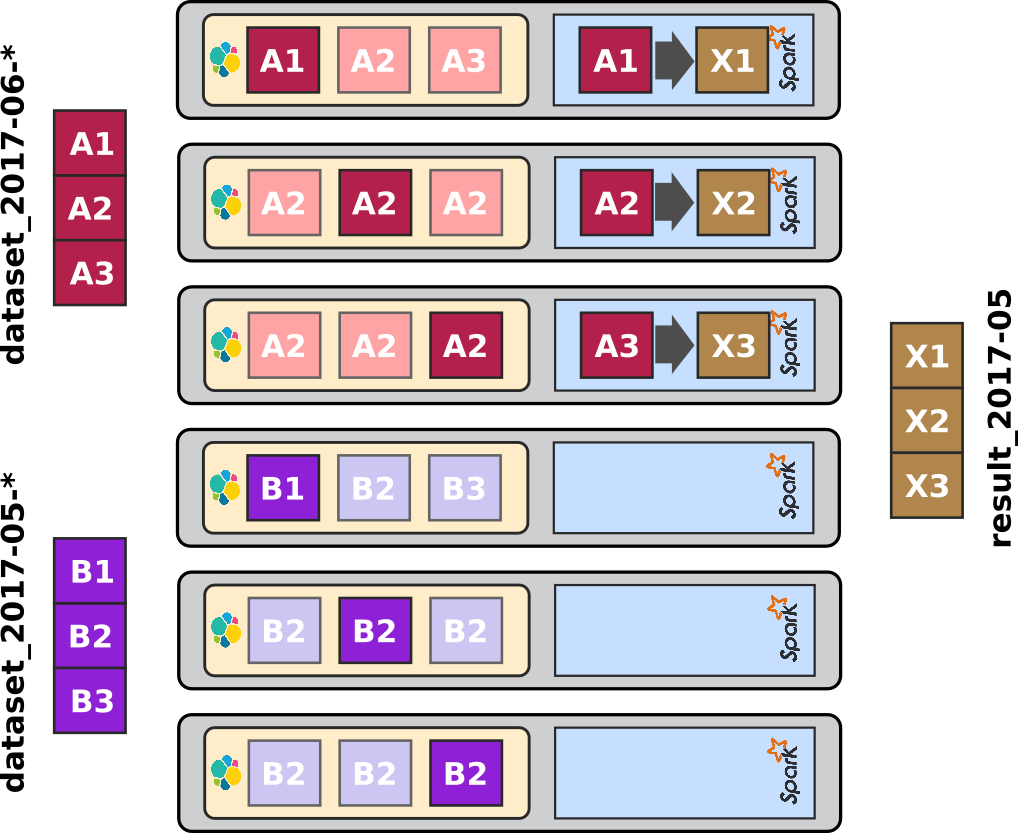
Three shards from ES need to be fetched to Spark. ES-Hadoop will create 3 partitions which leads to 3 tasks to be dispatched on the Spark processing stage. These 3 tasks will be executed on the 3 local ES nodes owning the shards.
Again, distributing the input data on one third of the ES cluster on one side, and limiting's Spark resources to the actual number of nodes required on the other side, leads to one third of the Spark cluster to be used for the spark processing.
In this case, the ElasticSearch data distribution strategy drives the workload distribution on spark.
Again replication is useful to ensure a successful distribution even under a loaded cluster.
Working on the whole period
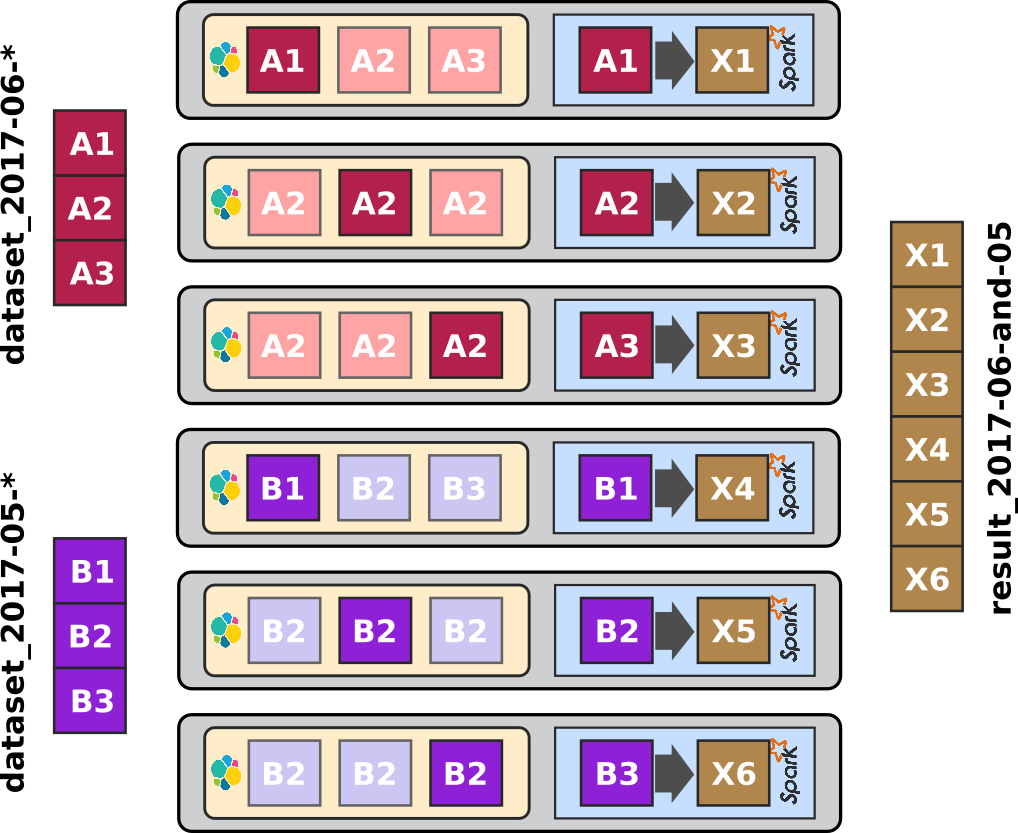
This will drive spark to create partitions on all nodes of the cluster.
The processing happens this way:
When working on the whole period, it happens fortunately in this case that we end up fetching shards from the whole ES cluster, in this case the whole spark cluster will be used to distribute the processing workload, since each and every local spark node will need to work on the local ES shard.
Again, one last time, the ElasticSearch data distribution strategy drives the workload distribution in good understanding to the data distribution, enforcing data-locality optimization.
4. Conclusion
In conclusion, having the ElasticSearch data distribution strategy driving the processing distribution on the Mesos / Spark cluster, thanks to the ES-Hadoop connector requirements given to spark, makes a lot of sense if you think of it.
First it's simple and consistent. One can understand how the first stages of processing will occur within spark by simply looking at the data distribution using for instance Cerebro. Everything is well predictable and straightforward to assess.
But more importantly, it's efficient since, well, whenever we store data in ElasticSearch, we think of the distribution strategy, in terms of index splitting, sharding and replication precisely for the single purpose of performance.
Creating too many indexes and shards, more that the amount of nodes, would be pretty stupid since having more than X shards to read per node, where X is the amount of CPUs available to ES on a node, leads to poor performances. As such, the highest limit is the amount of CPUs in the cluster. Isn't it fortunate that this is also the limits we want in such case for our spark processing cluster?
On the other hand, when one wants to store a tiny dataset, a single index and a single shard is sufficient. In this case, a processing on this dataset would also use a single node in the spark cluster. Again that is precisely what we want.
In the end, one "simply" needs to optimize his ElasticSearch cluster and the spark processing will be optimized accordingly.
Eventually, the processing distribution will scale linearly with the data distribution. As such, it's a very natural approach in addition to being simple and efficient.
Summing things up, the spark processing workload distribution being driven by the ElasticSearch data distribution, both are impacted by the following parameters of an ES index:
- The index splitting strategy
- The index sharding strategy
- The replication strategy (factor)
- The sharding key
The sharding key is not very important unless one has to implement a lot of joins in his processing scripts. In this case, one should carefully look at the various situations of these joins and find out which property is used most often as join key.
The sharding key should be this very same join key, thus enabling spark to implement the joins with best data locality, most of the time on the local node, since all shards with same sharding key end up on same node.
This may be the topic of another article on the subject, but likely not soon ... since, after so much writing, I need to focus on something else than Spark and ElasticSearch for a little while ...
As a last word on this topic for now, I would like to emphasize that not only this ELK-MS is working cool, in a simple, natural, efficient and performing way, but in addition all the UI consoles (Cerebro, Kibana, Mesos Console, Spark History Server) are state of the art, the Spark APIs is brilliantly designed and implemented, ElasticSearch itself in addition answers a whole range of use cases on its own, etc.
This stack is simply so amazingly cool.
Tags: big-data elasticsearch elk elk-ms kibana logstash mesos spark